
How to Use Coarray Fortran with MPI I/O
Author: Amasaki Shinobu (雨崎しのぶ)
Twitter: @amasaki203
Posted on: 2023-08-10 JST
Abstract
- Coarray is cooperatable with MPI on OpenCoarrays or Intel oneAPI environments.
- We can use MPI I/O, since the Fortran Standards does not define Parallel I/O.
- Then, let’s use together Coarray feature and MPI I/O-based libraries.
Contents
- Introduction
- Environments
- GNU Fortran Compiler + OpenCoarrays
- Intel oneAPI Fortran Compiler
- Parallel I/O
- Let’s Use Coarray with MPI I/O-based libraries.
- Conclusion
- Appendix
- Tested enviromnets
- Why can they use togather?
- Reference
Introduction
Coarray is the feature for parallelization built into the Fortran language which standardized at Fortran 2008. This includes parallel processing capabilities, but even the latest standards do not define for I/O parallelization features.
The conclusion is that the Coarray feature is able to use
cooperatively with the MPI library, and they can be used
together by NOT calling
mpi_init() and mpi_finalize().
Thus, the following code is buildable and executable:
program main
use, intrinsic :: iso_fortran_env
use mpi_f08
implicit none
integer(int32) :: petot, ierr
integer(int32) :: rank[*]
! absence of `call mpi_init`
call mpi_comm_size(mpi_comm_world, petot, ierr)
call mpi_comm_rank(mpi_comm_world, rank, ierr)
print '(a,i2,a,i2,a,i2,a,i2)', &
'This rank is ', rank, ' of ', petot,' | This image is ', this_image(), ' of ', num_images()
! absence of `call mpi_finalize`
end program mainwhere,
- the
mpi_comm_sizeprocedure stores the total number of the execution in its second argument, - the
mpi_comm_rankprocedure stores the process-specific identifier in its second argument, - the
num_images()function returns the total number of images of a coarray program execution, - and the
this_image()function returns the image-specific identifier of a coarray program execution.
Build the above code by specifying the directory with the
MPI library (location of the mpi_f08.mod,
e.g. /usr/lib64 on Gentoo Linux) using the linker
option -I.
% caf main.f90 -I/usr/lib64 -o ./a.outWhen executed with 8 processes, the following result is obtained:
% cafrun -n 8 ./a.out
This rank is 0 of 8 | This image is 1 of 8
This rank is 1 of 8 | This image is 2 of 8
This rank is 2 of 8 | This image is 3 of 8
This rank is 4 of 8 | This image is 5 of 8
This rank is 5 of 8 | This image is 6 of 8
This rank is 6 of 8 | This image is 7 of 8
This rank is 7 of 8 | This image is 8 of 8
This rank is 3 of 8 | This image is 4 of 8This compatibility will be helpful for Parallel I/O in a Fortran program, and it can also be used in conjunction with libraries dependent on MPI.
Environment
Compilers
The environments passed the test code are detailed in Appendix below.
- GNU Fortran + OpenCoarrays
- Intel oneAPI HPC toolkits
Note: According to my friend, the NAG Fortran Compiler for Windows is not capable of building the above code. I don’t have information regarding the Linux version or its multi-node version.
Note: As of 2023, LLVM/Flang does not yet support Coarray feature of the Fortran 2008.
Cluster configuration
Interconnection: Gigabit ethernet
Filesystem: NFS v4
Operating System: Gentoo Linux (kernel 6.1.31)
MPI Library: OpenMPI version 4.1.4
Parallel I/O
In the topic of program parallelization, the focus is often on parallelizing computational processes. On the other hand, however, when dealing with large-scale data, whether numerous or massive files, data input/output becomes an essential process that cannot be ignored.
In parallel programs, there are several approaches to handle input/output:
- The “each process reads from or writes to each file” approach.
- The “aggregate data one process” approach.
- The “direct access to one file from multiple processes” approach.
- The MPI I/O approach.
In the following, we will examine the characteristics of the above three approaches, with a specific focus on examining how each approach handles file writes. Additionally, we will explore how to “parallelize input/output” using MPI I/O in order to overcome bottlenecks.
“Each process, each file” approach
Each process launched in parallel independently performs write operations into separate files that remain untouched by other processes. This is the simplest approach and does not require the use of coarray variables. In the figure below, PE1(processor element one), PE2, PE3, PE4 access thier corresponding data files 1, 2, 3, 4.
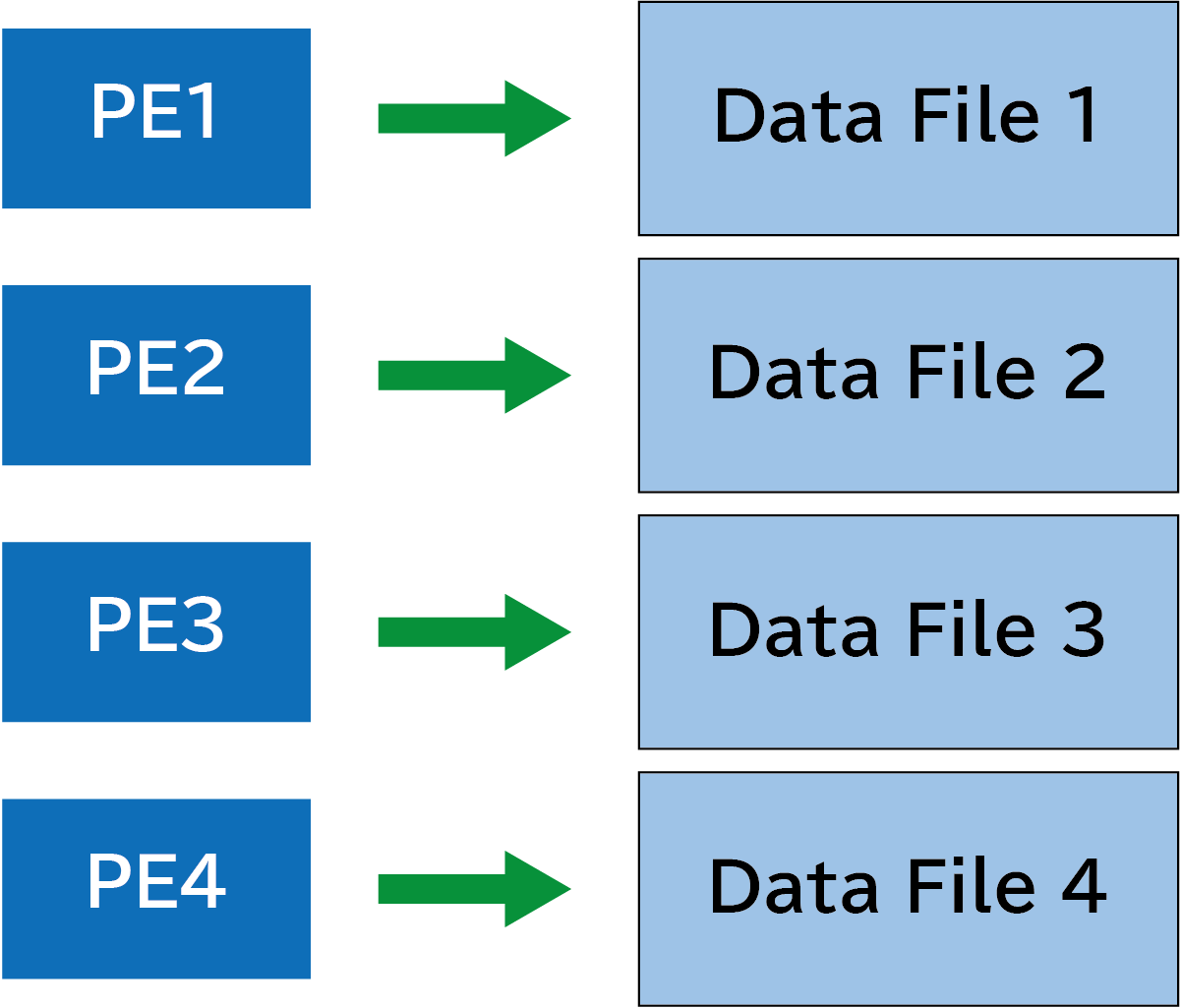
The advantages of this approach are as follows:
- No communication is required.
- It can scale the degree of parallel execution.
- It does not require parallel file system, e.g. NFS, Lustre.
- It can ensure data consistency.
The only significant drawback is that the number of files incleases in proportion to the degree of parallel execution. Consequently, the post-processing workload after writing data becomes a concern.
“Aggregate data one process” approach
Next, let’s consider an approach where the data to be written is aggregated to a single process, which will be responsible for performing the write operation. In this approach, each process needs to gather the data it holds to a specific designated process. As shown in the figure below, initially, the data held by PE2, PE3, and PE4 are transferred to PE1, and then PE1 performs the write operation.
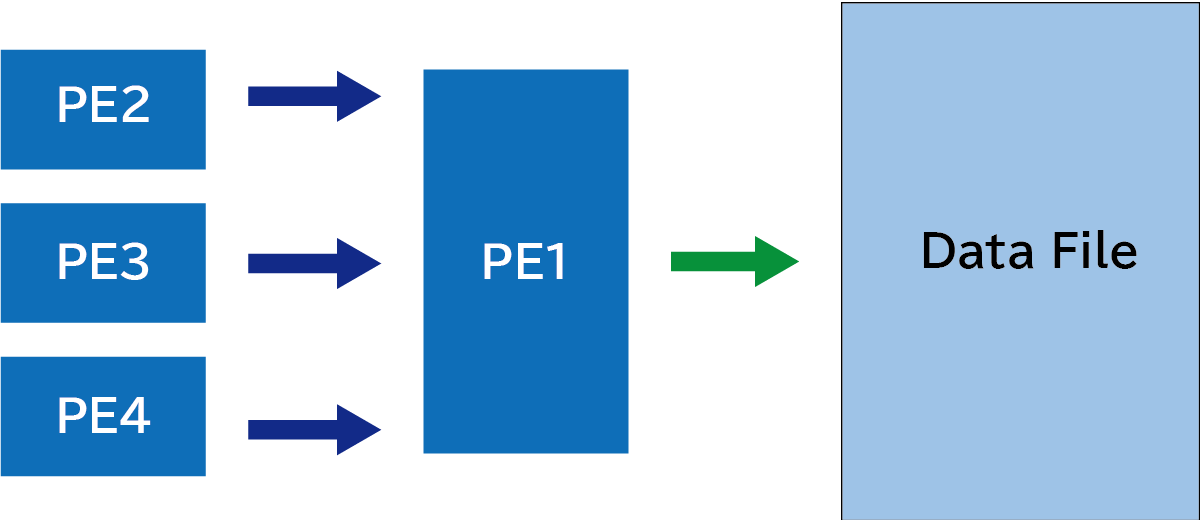
The following code prepares an array recv to
recieve data only when this_image() is equal to 1
(i.e. PE1). It then receives data from other images and
subsequently writes it to a file.
program main
implicit none
integer :: i, outuni
integer :: dat[*]
integer, allocatable :: recv(:)
! If the image number is 1, allocate the integer array 'recv'.
if (this_image() == 1) then
allocate(recv(num_images()))
end if
! Coarray variable stores the value of function this_image().
dat = this_image()
! If the image number is 1,
if (this_image() == 1) then
! the array 'recv' receives the value of the coarray variable 'dat'
! corresponding to its index number,
recv(1) = dat
do i = 2, num_images()
recv(i) = dat[i]
end do
! and then this process output a binary file.
open(newunit=outuni, file='out.bin', form='unformatted', &
access='stream', status='replace')
write(outuni) recv(:)
close(outuni)
deallocate(recv)
end if
end program mainWhen running this code with 64 processes, it outputs a
single out.bin file. This out.bin
contains 64 sets of 4-byte integers, stored consecutively for a
total of 256 bytes.
% caf main.f90 -o a.out
% cafrun -n 64 ./a.out
% hexdump out.bin
0000000 0001 0000 0002 0000 0003 0000 0004 0000
0000010 0005 0000 0006 0000 0007 0000 0008 0000
0000020 0009 0000 000a 0000 000b 0000 000c 0000
0000030 000d 0000 000e 0000 000f 0000 0010 0000
0000040 0011 0000 0012 0000 0013 0000 0014 0000
0000050 0015 0000 0016 0000 0017 0000 0018 0000
0000060 0019 0000 001a 0000 001b 0000 001c 0000
0000070 001d 0000 001e 0000 001f 0000 0020 0000
0000080 0021 0000 0022 0000 0023 0000 0024 0000
0000090 0025 0000 0026 0000 0027 0000 0028 0000
00000a0 0029 0000 002a 0000 002b 0000 002c 0000
00000b0 002d 0000 002e 0000 002f 0000 0030 0000
00000c0 0031 0000 0032 0000 0033 0000 0034 0000
00000d0 0035 0000 0036 0000 0037 0000 0038 0000
00000e0 0039 0000 003a 0000 003b 0000 003c 0000
00000f0 003d 0000 003e 0000 003f 0000 0040 0000
0000100This approach allows combining the output into a single file. It can be easily implemented using coarray, and it facilitates data consistency. It has, however, the following disadvantages:
- The load is concentrated on a speficic process (such as memory consumption, input/output processing, etc.).
- It cannot be scaled.
- The user needs to handle data communication.
Especially, the inability to scale can be a barrier in creating practical applications.
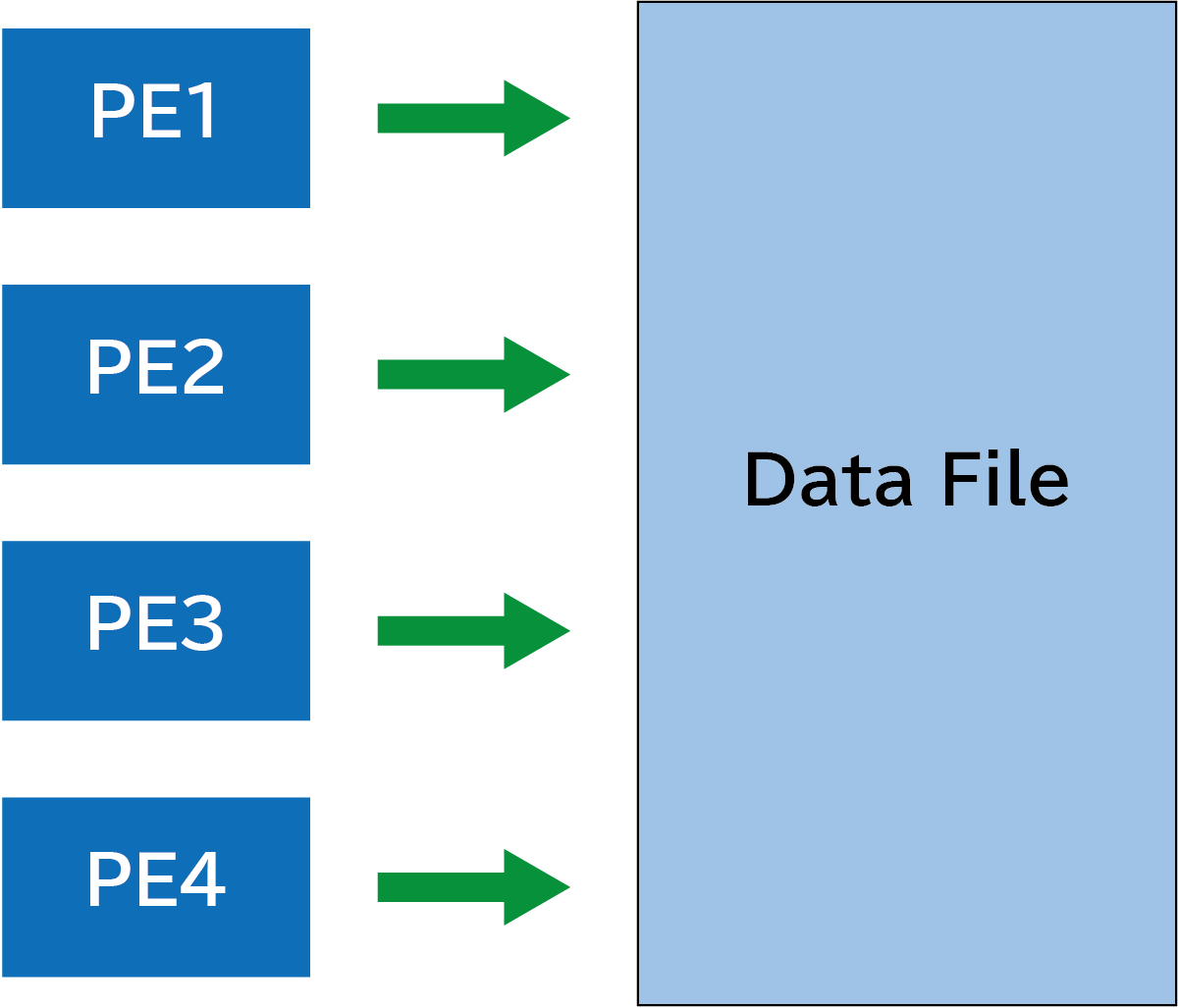
“Direct access to one file” approach
Thirdly, let’s discuss the approach of accessing a single
file directly from multiple processes. Here, “directly” means
writing data specific locations in the file, considering the
file as a byte sequence and specifying the file position. In
Fortran, this corresponds to opening the file with
access='direct' specified in the open
statement. As shown in the diabram below, PE1, PE2, PE3, and
PE4 independently, but simultaneously, operate
on a single shared file.
The following code is an example, in which the file is
filled with 0xFFFF (-1) during preprocessing, and
then each process writes 2 bytes at positions shifted by its
respective individual offsets.
program main
use, intrinsic :: iso_fortran_env
implicit none
integer :: length, outuni
integer(int16) :: dat, fill(256)
integer :: thisis, petot, ierr, offset
character(8), parameter :: out_file='out.bin'
dat = int(this_image(), int16) ! convert to 2-byte integer
fill(:) = -1 ! -1 will printed 'ffff' by hexdump
! Preprocessing
if (this_image() == 1) then
open(newunit=outuni, file=out_file, form='unformatted', &
access='stream', status='replace')
write(outuni) fill(:)
close(outuni)
end if
! End of preprocessing
sync all
! Read the byte length of the variable 'dat', and store it in the variable 'length'.
inquire (iolength=length) dat
! Define offset for writing at which record from the beginning of the file.
offset = 1 + (this_image() - 1)*2 !
! Execute the open statement with the `access='direct'` specifier.
open(newunit=outuni, file=out_file, access='direct', recl=length, status='old')
! Write data from each image.
write(outuni, rec=offset) dat
! Close file
close(outuni)
sync all
end program mainWhen running the above code with a parallel degree of 64,
out.bin contains 2-byte integers written in
increments of 2 bytes, up to 0x40 (64).
% caf main.f90
% cafrun -n 64 ./a.out
% hexdump out.bin
0000000 0001 ffff 0002 ffff 0003 ffff 0004 ffff
0000010 0005 ffff 0006 ffff 0007 ffff 0008 ffff
0000020 0009 ffff 000a ffff 000b ffff 000c ffff
0000030 000d ffff 000e ffff 000f ffff 0010 ffff
0000040 0011 ffff 0012 ffff 0013 ffff 0014 ffff
0000050 0015 ffff 0016 ffff 0017 ffff 0018 ffff
0000060 0019 ffff 001a ffff 001b ffff 001c ffff
0000070 001d ffff 001e ffff 001f ffff 0020 ffff
0000080 0021 ffff 0022 ffff 0023 ffff 0024 ffff
0000090 0025 ffff 0026 ffff 0027 ffff 0028 ffff
00000a0 0029 ffff 002a ffff 002b ffff 002c ffff
00000b0 002d ffff 002e ffff 002f ffff 0030 ffff
00000c0 0031 ffff 0032 ffff 0033 ffff 0034 ffff
00000d0 0035 ffff 0036 ffff 0037 ffff 0038 ffff
00000e0 0039 ffff 003a ffff 003b ffff 003c ffff
00000f0 003d ffff 003e ffff 003f ffff 0040 ffff
0000100This approach offers the following advantages:
- Avoiding communication overhead,
- Scalablity with the number of processes,
- Combining files into a single one.
However, a significant drawback is the difficulty in maintaining data consistency.
Note: In Intel Fortran, when performing input/output
operations at the byte level, you need to specify the
compilation option -assume byterecl.
MPI I/O
MPI I/O refers to an API subset of the MPI (Message Passing Interface) introduced in its version 2.0 (1998) that is designed for parallel input/output operations. In this approach, applications perform data reading and writing indirectly through procedures defined in MPI, rather than accessing files directly. Leverraging features like blocking and collective communication, which a well-supported in MPI, users can maintain data consistency while handling files, resulting in more effective data handling compared to direct file access.
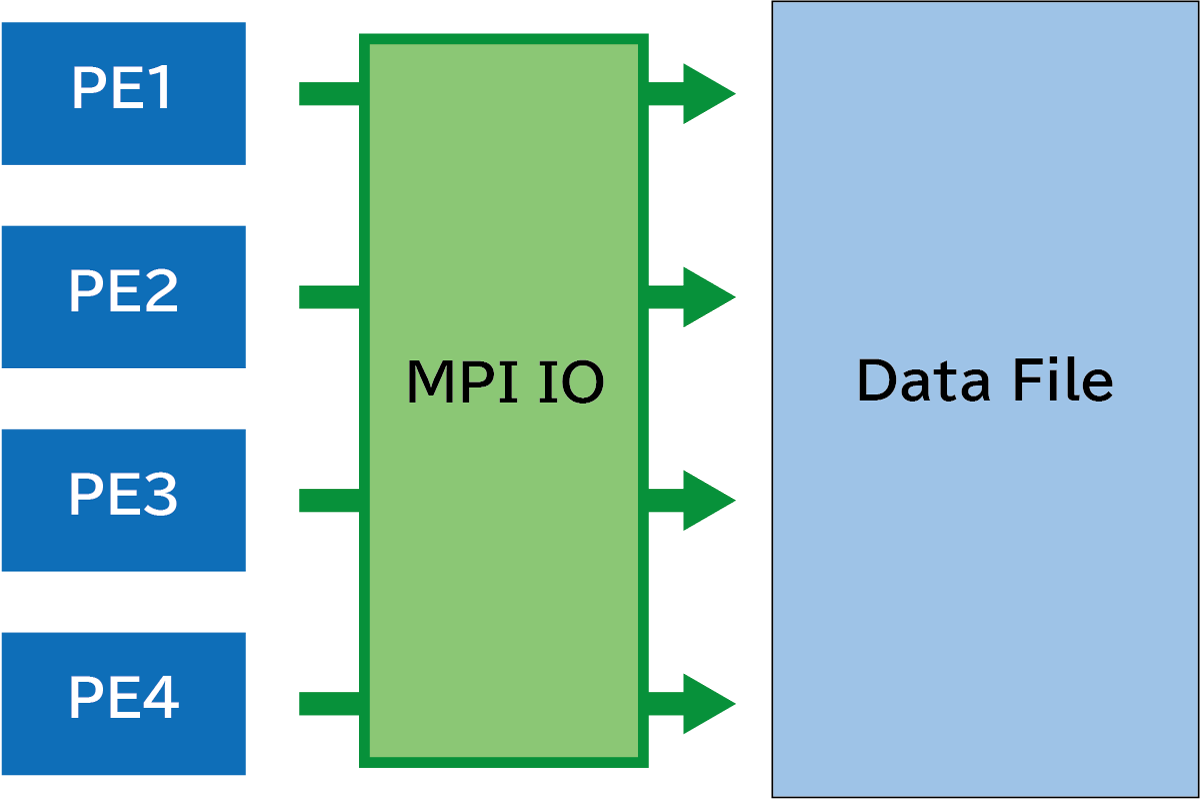
program main
use, intrinsic :: iso_fortran_env
use mpi_f08
implicit none
integer :: i
character(len=7), parameter :: filename='out.bin'
integer :: outuni
integer(int16) :: fill(512)
integer,parameter :: count = 8
integer(int16) :: buf(count)[*]
! for MPI I/O
integer :: ierr, amode, whence
integer(MPI_OFFSET_KIND) :: offset
type(MPI_INFO) :: info
type(MPI_FILE) :: fh
type(MPI_STATUS) :: stat
integer :: resultlen
character(len=MPI_MAX_ERROR_STRING) :: err_message
integer :: rank
! Preprocessing
fill(:) = -1
if (this_image() == 1) then
open (newunit=outuni, file=filename, form='unformatted', access='stream', status='replace')
write(outuni) fill(:)
close(outuni)
end if
sync all
! End of preprocessing
! Create data
if (this_image() == 1) then
buf(:) = int(this_image(), int16)
end if
call co_broadcast(buf, source_image=1)
do i = 1, count
buf(i) = buf(i) * this_image()
end do
! MPI I/O
info = MPI_INFO_NULL
amode = MPI_MODE_WRONLY + MPI_MODE_CREATE
call mpi_file_open(mpi_comm_world, filename, amode, info, fh, ierr)
call print_error_message(ierr)
offset = 16
whence = MPI_SEEK_SET
call mpi_file_seek_shared (fh, offset, whence, ierr)
call print_error_message(ierr)
call mpi_file_write_shared(fh, buf, count, MPI_INTEGER2, stat, ierr)
call print_error_message(ierr)
call mpi_file_close(fh, ierr)
call print_error_message(ierr)
contains
subroutine print_error_message (ierr)
implicit none
integer, intent(in) :: ierr
character(MPI_MAX_ERROR_STRING) :: message
integer :: resultlen
if (ierr /= 0) then
call mpi_error_string(ierr, message, resultlen)
print *, trim(message)
end if
end subroutine print_error_message
end program main The explanation of the MPI I/O procedure is as follows (for more details, please refer to the MPI specification and the library documentation):
- The
mpi_file_openprocedure opens the file specified byfilenamewith the mode specifiedamodeand associates it with the file header variablefh. - The
mpi_file_seek_sharedprocedure seeks the read/write position of the specified file header by the value ofoffset, ifwhenceis set toMPI_SEEK_SET. - The
mpi_file_write_sharedprocedure performs a blocking write ofcountelements from the variablebuf, which are treated asMPI_INTEGER2type, at the position pointed byfh(the order of writing is unspecified). - The
mpi_file_closeprocedure closes the file pointed byfh.
When running the program with a parallel degree of 64, it
outputs a single file out.bin. The content of
out.bin shows that data is stored starting from
the 17th byte, skipping the first 16 bytes, up to 528th byte
(512 bytes in total),.
% caf test/mpiio.f90 -I/usr/lib64
% cafrun -n 64 ./a.out && hexdump out.bin
0000000 ffff ffff ffff ffff ffff ffff ffff ffff
0000010 0001 0001 0001 0001 0001 0001 0001 0001
0000020 0033 0033 0033 0033 0033 0033 0033 0033
0000030 002b 002b 002b 002b 002b 002b 002b 002b
0000040 0025 0025 0025 0025 0025 0025 0025 0025
0000050 0016 0016 0016 0016 0016 0016 0016 0016
0000060 0022 0022 0022 0022 0022 0022 0022 0022
0000070 003d 003d 003d 003d 003d 003d 003d 003d
0000080 000e 000e 000e 000e 000e 000e 000e 000e
0000090 0008 0008 0008 0008 0008 0008 0008 0008
00000a0 001d 001d 001d 001d 001d 001d 001d 001d
00000b0 003a 003a 003a 003a 003a 003a 003a 003a
00000c0 0003 0003 0003 0003 0003 0003 0003 0003
00000d0 0030 0030 0030 0030 0030 0030 0030 0030
00000e0 002a 002a 002a 002a 002a 002a 002a 002a
00000f0 0017 0017 0017 0017 0017 0017 0017 0017
0000100 0015 0015 0015 0015 0015 0015 0015 0015
0000110 000d 000d 000d 000d 000d 000d 000d 000d
0000120 0009 0009 0009 0009 0009 0009 0009 0009
0000130 001a 001a 001a 001a 001a 001a 001a 001a
0000140 002f 002f 002f 002f 002f 002f 002f 002f
0000150 001e 001e 001e 001e 001e 001e 001e 001e
0000160 0036 0036 0036 0036 0036 0036 0036 0036
0000170 0018 0018 0018 0018 0018 0018 0018 0018
0000180 0035 0035 0035 0035 0035 0035 0035 0035
0000190 000f 000f 000f 000f 000f 000f 000f 000f
00001a0 0027 0027 0027 0027 0027 0027 0027 0027
00001b0 003b 003b 003b 003b 003b 003b 003b 003b
00001c0 0039 0039 0039 0039 0039 0039 0039 0039
00001d0 0020 0020 0020 0020 0020 0020 0020 0020
00001e0 001c 001c 001c 001c 001c 001c 001c 001c
00001f0 0011 0011 0011 0011 0011 0011 0011 0011
0000200 0038 0038 0038 0038 0038 0038 0038 0038
0000210 0029 0029 0029 0029 0029 0029 0029 0029
0000220 0032 0032 0032 0032 0032 0032 0032 0032
0000230 0031 0031 0031 0031 0031 0031 0031 0031
0000240 0006 0006 0006 0006 0006 0006 0006 0006
0000250 002e 002e 002e 002e 002e 002e 002e 002e
0000260 003f 003f 003f 003f 003f 003f 003f 003f
0000270 0004 0004 0004 0004 0004 0004 0004 0004
0000280 0021 0021 0021 0021 0021 0021 0021 0021
0000290 0037 0037 0037 0037 0037 0037 0037 0037
00002a0 0005 0005 0005 0005 0005 0005 0005 0005
00002b0 0028 0028 0028 0028 0028 0028 0028 0028
00002c0 0014 0014 0014 0014 0014 0014 0014 0014
00002d0 000b 000b 000b 000b 000b 000b 000b 000b
00002e0 0007 0007 0007 0007 0007 0007 0007 0007
00002f0 000c 000c 000c 000c 000c 000c 000c 000c
0000300 0040 0040 0040 0040 0040 0040 0040 0040
0000310 002c 002c 002c 002c 002c 002c 002c 002c
0000320 0034 0034 0034 0034 0034 0034 0034 0034
0000330 003c 003c 003c 003c 003c 003c 003c 003c
0000340 001b 001b 001b 001b 001b 001b 001b 001b
0000350 0023 0023 0023 0023 0023 0023 0023 0023
0000360 0013 0013 0013 0013 0013 0013 0013 0013
0000370 002d 002d 002d 002d 002d 002d 002d 002d
0000380 0010 0010 0010 0010 0010 0010 0010 0010
0000390 001f 001f 001f 001f 001f 001f 001f 001f
00003a0 0002 0002 0002 0002 0002 0002 0002 0002
00003b0 0012 0012 0012 0012 0012 0012 0012 0012
00003c0 0026 0026 0026 0026 0026 0026 0026 0026
00003d0 003e 003e 003e 003e 003e 003e 003e 003e
00003e0 0024 0024 0024 0024 0024 0024 0024 0024
00003f0 0019 0019 0019 0019 0019 0019 0019 0019
0000400 000a 000a 000a 000a 000a 000a 000a 000a
0000410 ffff ffff ffff ffff ffff ffff ffff ffff
0000420
MPI I/O-based parallel I/O has the following characteristics:
- It can scale with the degree of parallel execution.
- Communication is not explicitly required to be written by the user.
- Data consistency is easier to maintain compared to direct access.
Let’s Use Coarray with MPI I/O-based libraries
As discussed above, it has been confirmed that MPI libraries
and Coarray can be used simultaneously. This implies that I/O
libraries implemented with MPI I/O can also be combined with
Coarray. In fact, this assumption is correct, and for example,
when using the NetCDF Fortran Library, by specifying
use mpi_f08 and use netcdf, the
program can be built and executed, producing the correct
.nc file. Below is part of a code for generating a
.nc file.
program main
use, intrinsic :: iso_fortran_env
use :: mpi_f08
use :: netcdf
! ...
thisis = this_image()
block ! Define nc
call check( nf90_create_par(trim(out_nc_file), NF90_HDF5, comm%mpi_val, info%mpi_val, ncid) )
call check( nf90_def_dim(ncid, 'x', nx, dim_id_x) )
call check( nf90_def_dim(ncid, 'y', ny, dim_id_y) )
call check( nf90_def_var(ncid, 'x', NF90_DOUBLE, dim_id_x, var_id_x))
call check( nf90_def_var(ncid, 'y', NF90_DOUBLE, dim_id_y, var_id_y))
call check( nf90_def_var(ncid, 'elevation', NF90_DOUBLE, [dim_id_x, dim_id_y], var_id_elevation, deflate_level=1 ))
call check( nf90_put_att(ncid, var_id_x, 'units', 'meter') )
call check( nf90_put_att(ncid, var_id_y, 'units', 'meter') )
call check( nf90_put_att(ncid, var_id_elevation, 'units', 'meter') )
call check( nf90_enddef(ncid) )
end block
! ...
! Write x-axis and y-axis into nc
block
call check( nf90_put_var(ncid, var_id_x, x, start=[n_begin_x], count=[local_nx(thisis)]))
if (thisis == 1) then
call check( nf90_put_var(ncid, var_id_y, y, start=[1], count=[ny] ))
end if
end block
! ...
! Write main data
block
allocate(local_data(1:local_nx(thisis), ny))
local_data(:,:) = thisis
start_nc = [n_begin_x, 1]
count_nc = [local_nx(thisis), local_ny(thisis)]
call check( nf90_put_var(ncid, var_id_elevation, local_data, start=start_nc, count=count_nc))
end block
call check(nf90_close(ncid))
contains
subroutine check(status)
implicit none
integer, intent(in) :: status
integer :: ierr
if(status .ne. NF90_noerr) then
print '(a,i3,a)', 'Image: ', this_image(), ': '//trim(nf90_strerror(status))
error stop
end if
end subroutine check
end program mainThe entire code is available from the file on GitHub repository. Compilation, execution, and the results are as follows.
% caf netcdf-with-coarray_1-dim-block-division.f90 -I/usr/lib64 -I/usr/include -lnetcdff
% cafrun -n 64 ./a.out
% ncdump out.nc | head -n 20
netcdf out {
dimensions:
x = 1024 ;
y = 1024 ;
variables:
double x(x) ;
x:units = "meter" ;
double y(y) ;
y:units = "meter" ;
double elevation(y, x) ;
elevation:units = "meter" ;
data:
x = 0, 0.0009765625, 0.001953125, 0.0029296875, 0.00390625, 0.0048828125,
0.005859375, 0.0068359375, 0.0078125, 0.0087890625, 0.009765625,
0.0107421875, 0.01171875, 0.0126953125, 0.013671875, 0.0146484375,
0.015625, 0.0166015625, 0.017578125, 0.0185546875, 0.01953125,
0.0205078125, 0.021484375, 0.0224609375, 0.0234375, 0.0244140625,
0.025390625, 0.0263671875, 0.02734375, 0.0283203125, 0.029296875,
0.0302734375, 0.03125, 0.0322265625, 0.033203125, 0.0341796875, 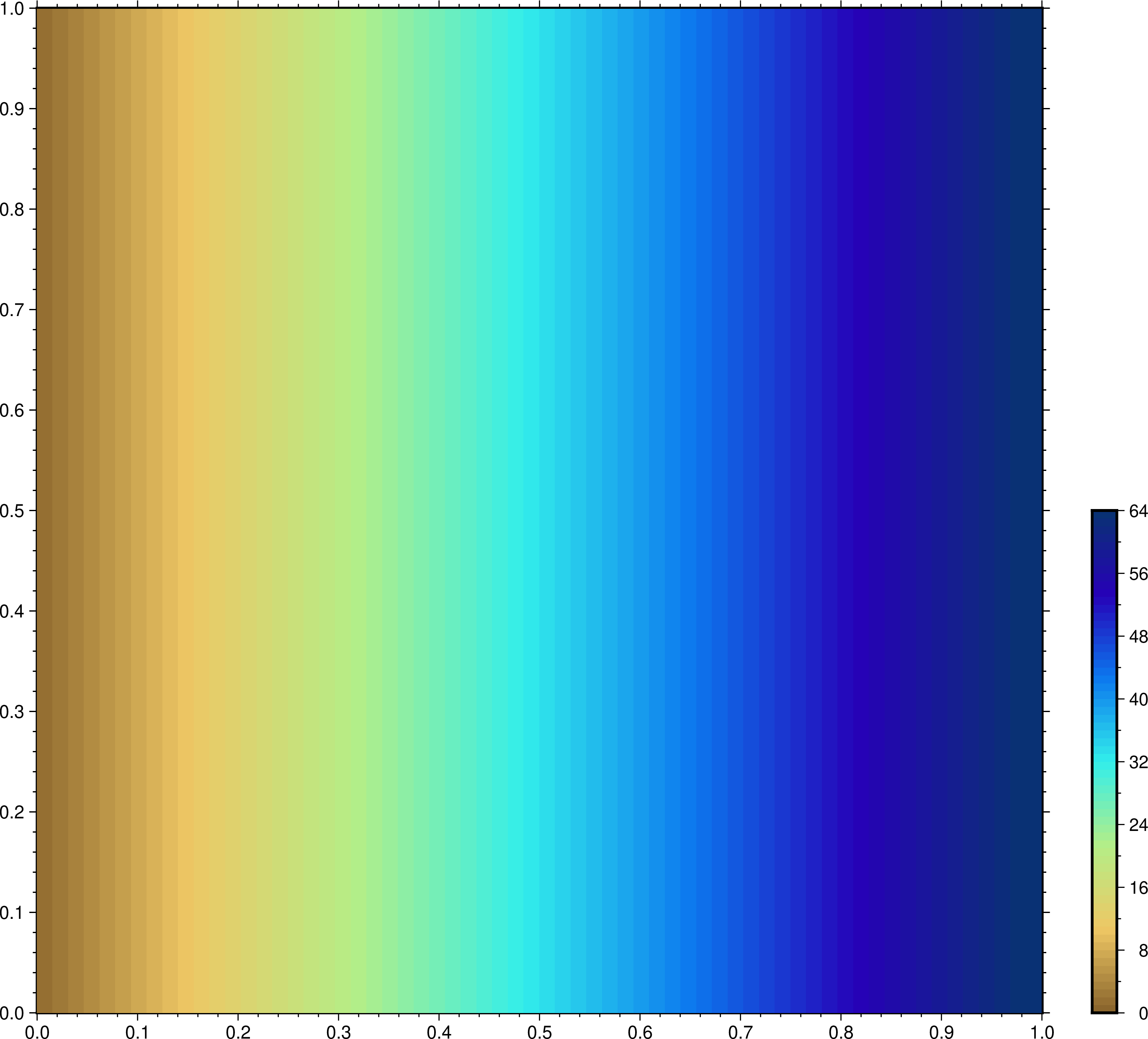
I used Generic Mapping Tools v6.4.0 for plotting the NetCDF file.
Notes:
To do this, you need to use HDF5 and NetCDF libraries built with MPI support to enable parallelization. In order to check whether parallelization is enabled or disabled for NetCDF library, you can execute the command
nc-config --has-parallel --has-parallel4.To run this code with
gfortran, you need to use a binary of OpenMPI that has been built with ROMIO enabled.
Conclusion
This article discuss the compatibility of Fortran’s Coarray feature with the MPI libraries. While Coarray provides parallelization capabilities within the language, it lacks sufficient suport for I/O operations. The MPI libraries, however, can handle this aspect effectively. Some discussions over whether to use Coarray or MPI is not uncommon, but the combination of both allows for a practical approach, with MPI taking on the role of handling I/O operations. This provides a novel technique for Fortran programmers who develop practical applications.
Appendix
Tested environments
- Hardware
- HP Proliant ML350 Gen9 (dual Intel Xeon E5-2683 v4)
- HP Proliant ML110 Gen9 (single Intel Xeon E5-2683 v4)
- Interconnection
- Gigabit Ethernet
- NFS v4
- System (Linux)
- Gentoo Linux (Kernel v6.1.31)
- Ubuntu Server 22.04.3 LTS
- Compilers
GCC
GNU Fortran
% gfortran --version GNU Fortran (Gentoo 12.3.1_p20230526 p2) 12.3.1 20230526 Copyright (C) 2022 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.OpenCoarrays
% caf --version OpenCoarrays Coarray Fortran Compiler Wrapper (caf version 2.10.1) Copyright (C) 2015-2022 Sourcery Institute Copyright (C) 2015-2022 Archaeologic Inc. OpenCoarrays comes with NO WARRANTY, to the extent permitted by law. You may redistribute copies of OpenCoarrays under the terms of the BSD 3-Clause License. For more information about these matters, see the file named LICENSE that is distributed with OpenCoarrays.OpenMPI
% mpirun --version mpirun (Open MPI) 4.1.4 Report bugs to http://www.open-mpi.org/community/help/Intel oneAPI
% mpiifort --version ifort (IFORT) 2021.10.0 20230609 Copyright (C) 1985-2023 Intel Corporation. All rights reserved. % mpirun --version Intel(R) MPI Library for Linux* OS, Version 2021.10 Build 20230619 (id: c2e19c2f3e) Copyright 2003-2023, Intel Corporation.
Note
When using Intel oneAPI toolkits, it is necessary to utilize libraries built with Intel’s compiler for modules like HDF5 and NetCDF. As they could conflict with libraries installed by the system’s package manager during linking, care should be taken to avoid mixing libraries built with GCC and those built with the Intel’s compiler.
Questions
Question: Why is it possible to use Coarray and MPI
in conjunction by not calling mpi_init() and
mpi_finalize()?
Answer: According to the referrences [2, 3], both OpenCoarrays and Intel Fortran’s coarray implementation use MPI as their backend. I assume that this enables the coexistence of coarray feature and MPI library without conflicts, allowing for the unexpected direct invocation of MPI procedures.
Reference
- [Japanese ver.] Coarray FortranでMPI I/Oを使う | Qiita
- OpenCoarrays/README.md at main | GitHub
- Essential Guide to Distributed Memory Coarray Fortran with the Intel Fortran Compiler for Linux | Intel
Copyright 2023 Amasaki Shinobu